WordSynth
Link: http://wordsynth.latenthomer.com/
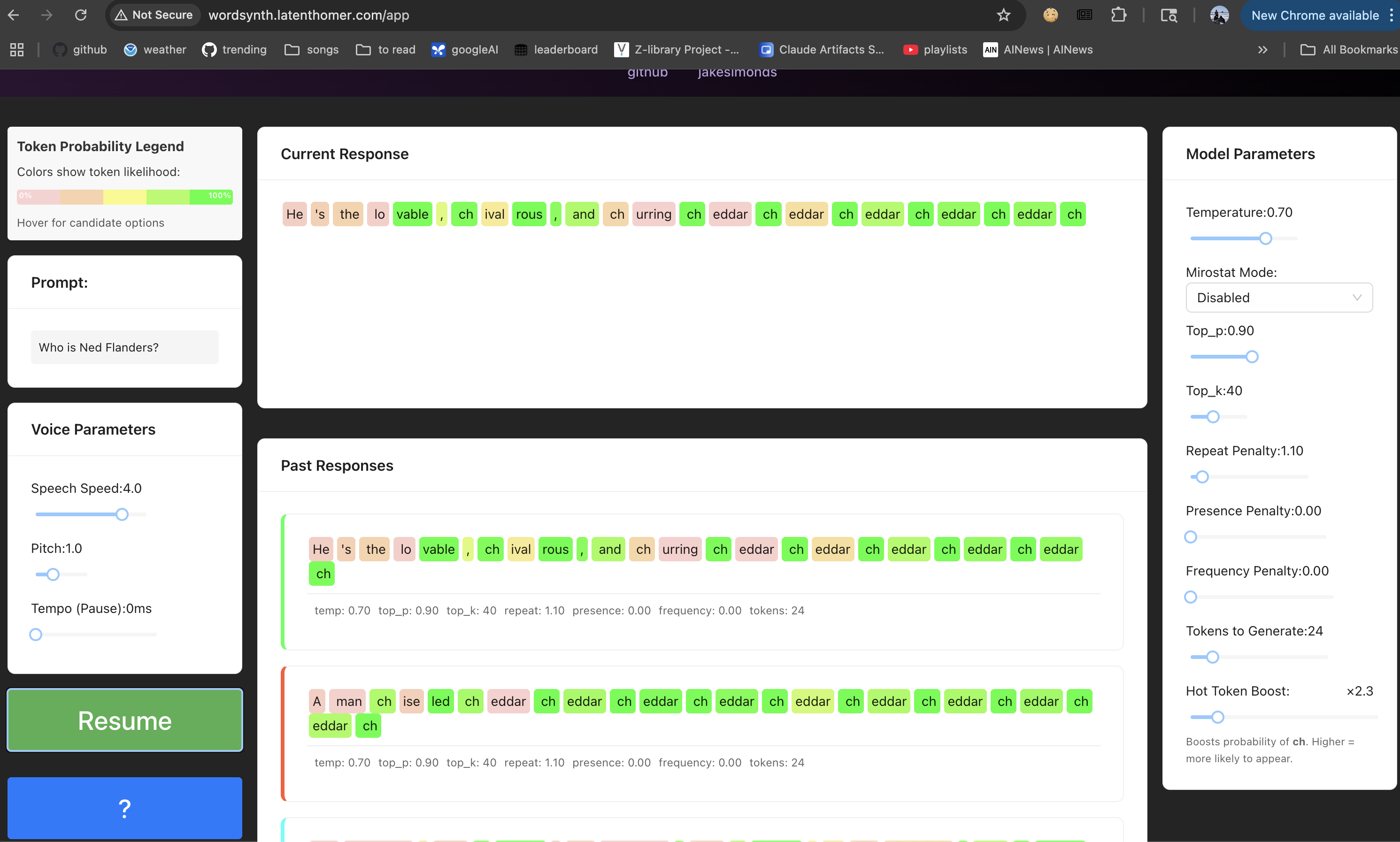 An example of the kinds of shenanigans you can get up to with WordSynth. Note ‘ch’ is the Hot Token and it has been boosted to 2.3, meaning the raw logit probability for ‘ch’ is boosted enough to make the LLM…act funny
An example of the kinds of shenanigans you can get up to with WordSynth. Note ‘ch’ is the Hot Token and it has been boosted to 2.3, meaning the raw logit probability for ‘ch’ is boosted enough to make the LLM…act funny
What is it?
Word Synth is llama3.2-1b, so a really tiny LLM, with inference provided by llama.cpp, and the sampling parameters that were relatively straightforward to expose are exposed.
So you pick one prompt, and then you just kinda watch it generate over and over again and see how the different sampling parameters alter generation.
Why’d you make it?
I have strong opinions, and one strong opinion I have is that when you chat with an LLM, you enter a headspace of ‘having a conversation’ which is very understandable, but gets you in a headspace of treating the LLM like a person, which it isn’t.
So this was an attempt to:
- 1: make an LLM app that doesn’t have a chat interface
- 2: see how far I could get doing roll-your-own inference and deployment
- 3: gain some intuition around sampling
Surprises/Delights
It was delightful & remains delightful to see the probabilities on the words, and you can almost ‘see’ the LLM decide what it’s going to say. An example of this is if you use the joke prompt, you can see the probabilities go high (tokens turn green) when it starts telling a joke, I think because much like me when I am telling a joke or anecdote I’ve told before, once I’m midway thru I kinda know where I’m going.
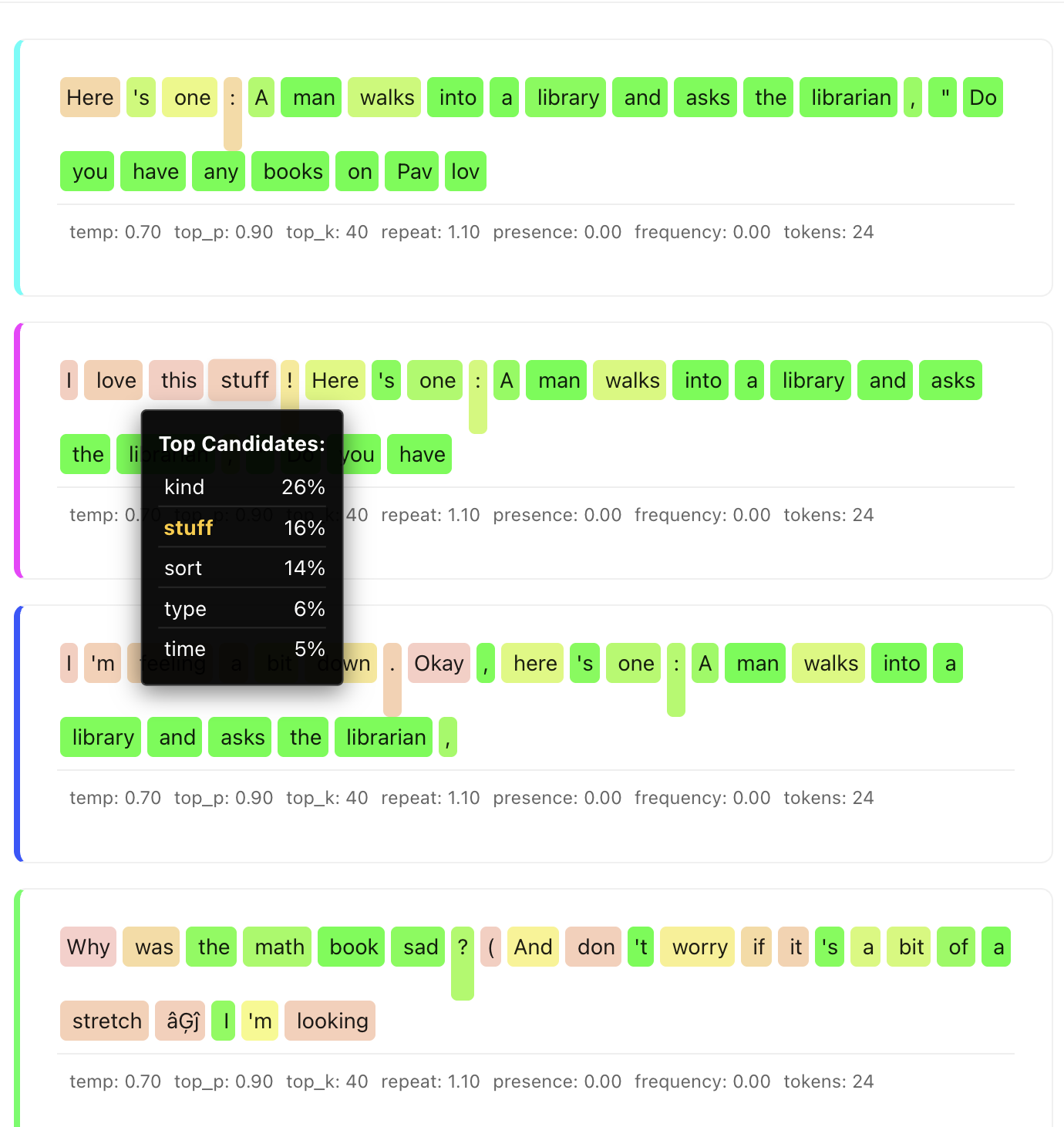 Note how the intro is different in these two generations but it finds the same joke
Note how the intro is different in these two generations but it finds the same joke
It was surprising to see the output become deterministic or near deterministic when any of Temperature, top_p or top_k were super low. Deterministic obviously you just see the same thing over and over again. But near deterministic it was interesting to just see almost a tree-structure (especially with top_k set to 2 or 3) of how the first token would be one of a couple options, which would then lead to a second token of a couple options, etc.
The Hot Token Boost was my attempt to just jump into the logits and see how far a very simple idea (that idea being: can I boost one token artificially?) could get me. I was kinda hoping to almost make the model use the Hot Token unnaturally. Which it does, but you have to fuss with the hot token boost because if its too high, you just get that token over and over again, but just a little bit lower than that and its almost ignored.
Frustrations
I kind of feel like I still don’t understand sampling in a deep sense even after implementing this. So that’s a frustration.
Also not a huge frustration but…this project if anything made LLMs as a technology feel more fragile, made me feel all the more surprised that any of this works at all.
It’s slow! On my local macbook (M4 macbook, mps, 24 GB memory) it’s wicked speedy, but I just kind of naively put it in a EC2 and its kinda slow enough that it’s less fun to mess with, since you don’t get the immediate satisfaction of adjusting the sliders and just seeing the instant results.
And I don’t know naively how to make it much faster because I know there’s 10,000 inference providers out there, but I need one that’ll let me use llama.cpp in the weird way I’m using it. If anybody reading this knows how I can easily use a specialized inference provider I’m all ears! Otherwise probably going to take this site down in a bit (sorry if you’re reading this and that’s already happened).