Latent Homer: Toy Semantic Search with Simpsons Characters
Embeddings are Dope
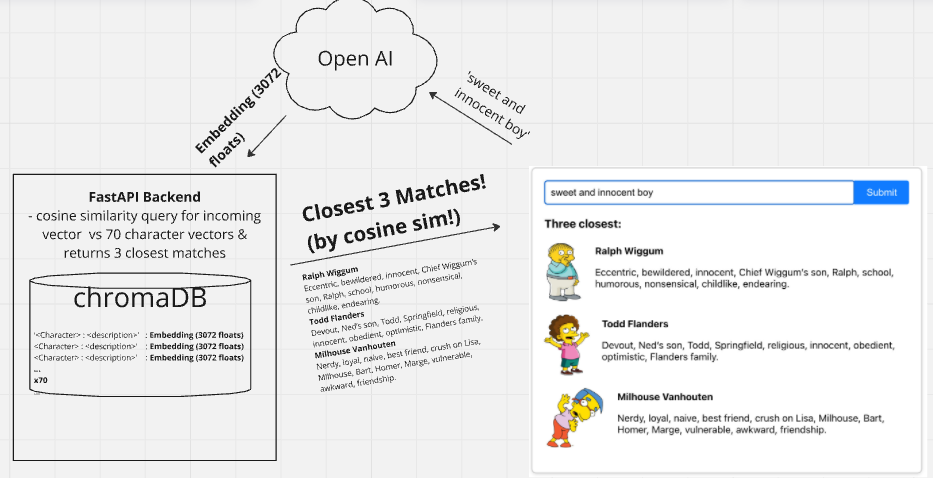
http://latenthomer.com is a very simple semantic search web app I built to teach myself about embeddings. The way it works is, I generated embeddings for one-sentence descriptions of 70 Simpsons characters and am storing them in a ChromaDB instance. You can go to the site, describe a person ((or type or person, i.e. ‘bad houseguest’, ‘classic personality hire’, ‘silly elderly man’…) or literally just input any string at all) and it’ll generate an embedding for your string, and then query my collection of character descriptions for matches based on cosine similarity.
How I’d explain embeddings to myself six months ago
Let’s imagine you have an old-fashioned store where you sit at a counter & people come in and ask you for things. One day somebody comes in and asks if you have a ’toque,’ or anything like it. You know you don’t have it, but how can you know if you have anything like it?
Suddenly you have this idea. You close the store for the afternoon, tape some butcher paper to the wall of your warehouse, and draw a HUGE two-dimensional graph. On the x-axis you label, Weight. Y-axis - Price. You then go through your entire inventory, weighing and noting the price of everything you have for sale. You end up with a graph that looks something like this:
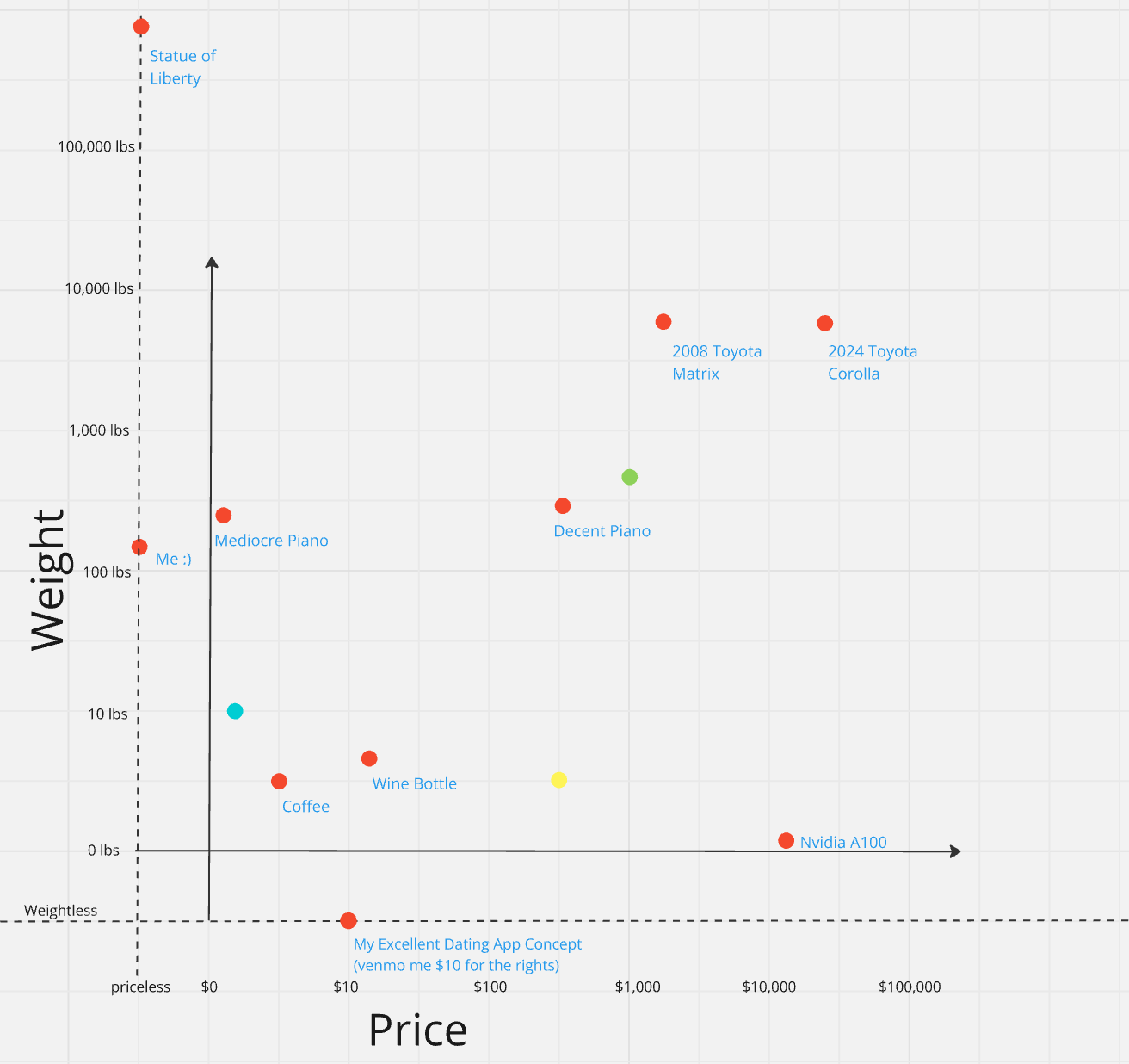
Sorry about the ecletic items, forgot about the fictional scenario while making the graph. Also placement of items is inexact & not important & if you’re confused right now look at the the blue, green and yellow dots. Which one is…a: Bag of potatoes, b: used scooter, c: laptop
The next day, somebody comes in and asks for a Ham Sandwich (you’re also a restaurant). You know you don’t have it, but with this new system in place you ask them: how much would this ‘Ham Sandwich’ weigh and cost? You then take their answers, go over to the big board, and mark the spot. Lo and behold, very close to that spot there’s a dot for ‘Turkey Panini’. ‘Turkey Panini’ and ‘Ham Sandwich’ are very different phrases, and no lexicographical search in the world would have gotten you close to this result, but but the cost-weight metrics captures something similar about them. Pretty cool!
Now just keep adding dimensions measuring different meaningful factors until you’ve got 768 (or 1024 or 3076) & you’re in business!
My Odyssey
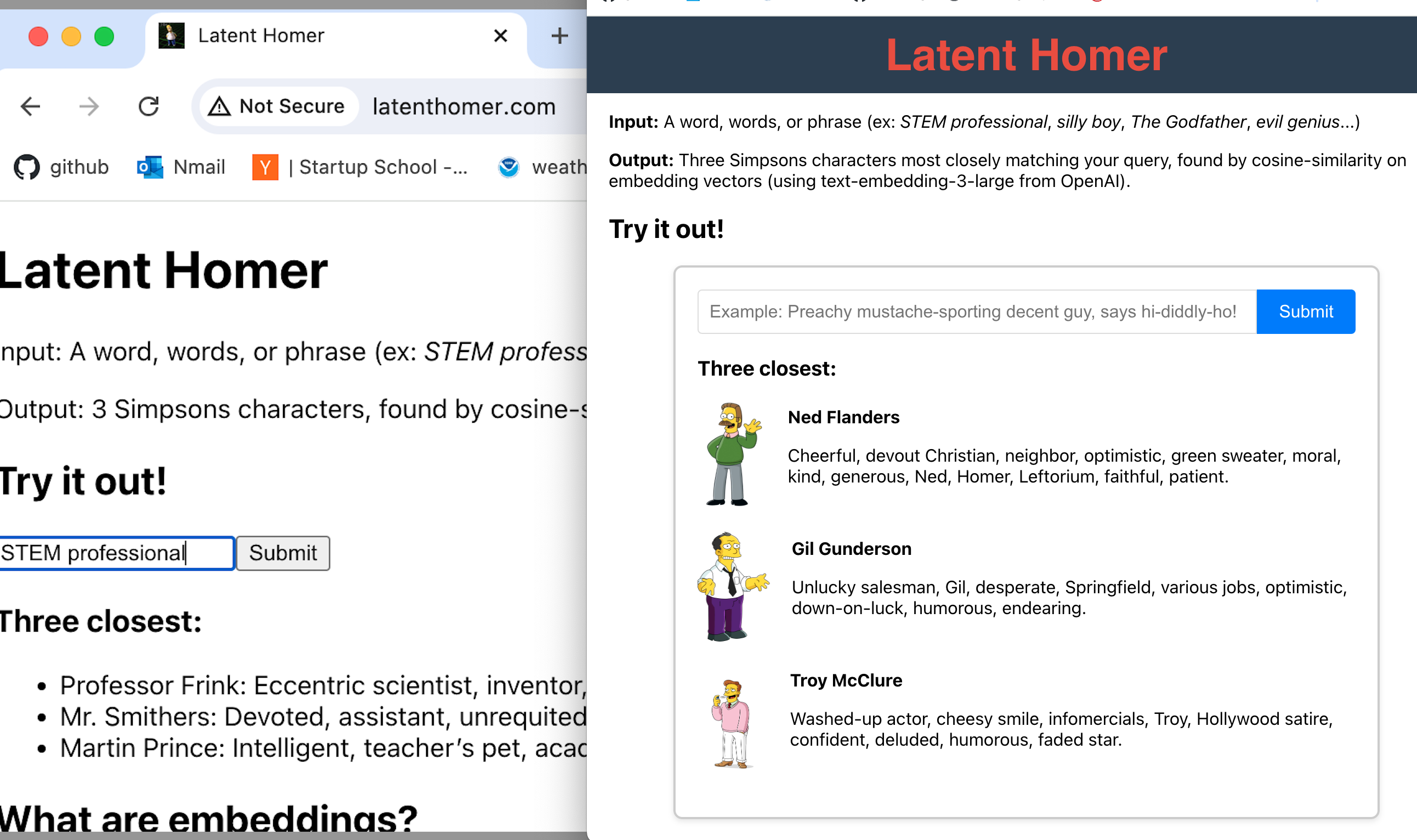
Embeddings are so easy that the hard part of this project was everything else.
couple quick Things I Learned
Embedding model quality varies & will depend on your use-case
I’m using OpenAI-large embeddings for my website because 1) my scale is small enough that I don’t care about the overhead of their size (3072, other ones I experimented with maxed out at 1024), 2) they’re good embeddings & 3) they’re cheap & the API was easy.
I also experimented (https://github.com/jakesimonds/Simpsons-react/tree/openAI/tests) with open embedding models hosted on my local macbook. The best of these were nearly as good as openAI-large, and a lot smaller.
Adjectives served me well
When I first was working on this project I thought I’d have to scrape a Simpsons wiki for data. Then I decided to just ask chatGPT to make the data for me. And it did. And that worked, but like not as well as I hoped. The descriptive strings it gave me were something along the lines of:
Principal Skinner: Principal Skinner is the Principal of Springfield Elementary, He has Vietnam War flashbacks, lives with his mother, often has conflicts with Bart Simpson, and the Superintendent (when the superintendent visits, things often go wrong
It occurred to me that a low-hanging fruit might be these descriptions, so then I asked chatGPT again–I told it my use-case & specifically asked for descriptive strings that would make good embeddings and I got results like this:
Principal Skinner: Authority, strict, school principal, Vietnam veteran, insecure, Seymour, Bart, Homer, disciplined, rigid, dedicated.
That made a huge-huge-huge difference.